
안녕하세요?
도쿄박입니다.
딥시크발 폭락에 따른 앞으로의 저와, 파이닉스의 생각을 이곳에 담도록 하겠습니다.
더이상 이 이상으로 딥시크로 인한 하락으로 인해 우왕좌왕 하는 모습 안봤으면 좋겠습니다.
가독성을 위하여 반말을 섞을 수 있으니 이 점 양해바랍니다.
1) 딥시크가 발표 됌.
2) 더 적은 비용으로, 더 나은 성능을 보여준다가 이 딥시크 LLM의 핵심임.
3) 더 적은 비용이 충격적인지, 더 나은 성능이 충격적인지 비교를 해봤을 때,
4) AI인프라의 타격이 심각한것으로 보아서 더 적은 비용에 방점을 찍은 움직임이 큼.
5) '더 적은 비용' 에 대한 몆가지 생각을 정리해보고자 함.
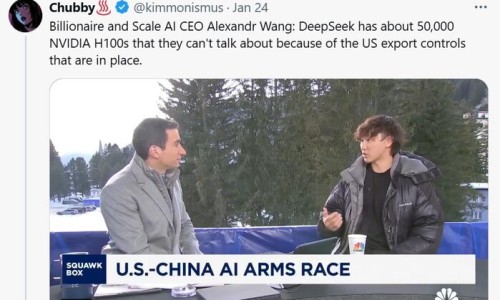
6) 첫째, 딥시크는 언론에 발표한 공식적인 GPU 칩 갯수에 비해서 과대 축소 되었음을 의심 중
7) 둘째, 딥시크의 더 적은 비용에 대한 기술적 측면에서의 의심
8) 첫째는 말 그대로 칩 갯수가 본래 투자 된 칩 비용에 비해 과대 축소 되었음을 일론머스크가 거의 확정적으로 보고 있음.
아래의 사진 대화내용을 축약해보면 딥시크가 헐값에 개발이 된것이 아니라고 얘기하고 있음.

또한, 아래의 뉴스 전문에서 살펴볼 수 있듯이 일론은 딥시크 관련한 적은 비용이라는 부분에 대한 발표를 거의 확정적으로 거짓이라고 얘기하는 중.
9) 사실 나는 지금 딥시크가 적은 비용으로 나은 성능을 이끌었다는 부분에 대해서 크게 의심을 하지 않음. 적은 비용이 맞다고 생각함.
10) 그런데, 적은 비용을 어떻게 해냈는가에 대한 부분을 짚고 싶음. 바로 두번째 논지인 기술적 측면임.
11) 이제부터 얘기 할 내용은 공학적인 부분이 있기 때문에 참조해주길 바람.
12) 테슬라의 FSD v12 발표 당시에 일론머스크가 가장 강조한 부분이 자율주행을 '저전력' 소모로 획기적인 비용 축소를 이끌어 냈다고 발표함.
13) 그렇게 가능한 이유는 변수의 자료형 범위를 FR16 에서 INT8로 설정을 하면서 부동소수점 연산을 자르고 비트의 수를 획기적으로 줄였기 때문임.
14) 현재 AI 학계에서는 AI의 정교한 출력을 위해서 많은 수의 연산을 할 필요없이 양질의 데이터를 취합해서 적은 자료형 범위만으로도 충분히 성능을 이끌어 낼 수 있다는 발표가 지속적으로 나오고 있음.
15) 아래의 자료를 살펴보면 알겠지만, 자료형 범위가 줄어들수록 효율성은 올라가지만 출력의 정확도는 다소 줄어드는 함수(상관관계)를 갖고 있는데, 이 함수의 효율성이 현재처럼 FR16 체계만큼 과도하게 설정 될 필요는 없다고 거의 가닥이 나오고 있다는 사실임.
-
![]() [주주잡설] 반도체 폭등장에서 소외되지 않는 방법2025.01.23.
[주주잡설] 반도체 폭등장에서 소외되지 않는 방법2025.01.23. -
![]() [주주잡설] TSMC 4분기 어닝콜, 그런데 CoWoS가 뭐야?2025.01.16.
[주주잡설] TSMC 4분기 어닝콜, 그런데 CoWoS가 뭐야?2025.01.16. -
![]() [주주속보] 젠슨 황 "양자컴퓨터, 아직 20년은 일러"2025.01.08.
[주주속보] 젠슨 황 "양자컴퓨터, 아직 20년은 일러"2025.01.08. -
![]() [주주잡설] 반도체 소부장 계급도 : 모멘텀 편2025.01.05.
[주주잡설] 반도체 소부장 계급도 : 모멘텀 편2025.01.05.




많이 본 콘텐츠
전일 00시~24시까지 집계한 결과입니다.

![[주주잡설] 공매도를 앞두고 숏 치기 알맞은 종목 리스트](https://scs-phinf.pstatic.net/MjAyNTAyMjBfMTM1/MDAxNzQwMDIzNzQ1NTM0.lnsrzzQ2Kf_908pOVPNgHPxcJlvZ5YCNbwVUSwKQdHMg.zVBK9sMblLK-e-D87dphgONdUEPqXEVm60mhtEdwqkgg.PNG/image.png?type=nfs260_260)

![[주담통화] 세경하이테크(148150) : 세스맷 퀄, 기사화는 언제?](https://scs-phinf.pstatic.net/MjAyNTAyMThfMjEz/MDAxNzM5ODQ3MzM5MzE5.ninIlGWPfiZzaIygUNmJhKNPLnHi3Snp4SWy7CSZEjEg.TaTBgKHrfhVgb8lSDi2hqyrkd4IuRhTtDiyaq1dHHcEg.PNG/1000022300.png?type=nfs260_260)
![[주주잡설] 사운드하운드(SOUN) 하락: 엔비디아의 13F에서 얻을 수 있는 투자 아이디어](https://scs-phinf.pstatic.net/MjAyNTAyMThfNDEg/MDAxNzM5ODg4MDc5ODQ4.lTadEBS7tKdKAQneiIpdWQfSJtvBPOLyIdPMC-RyoQ8g.vC-LppOCD4ud0JusFqp3S916Vuf_RK27-MZIuYUSYxgg.PNG/image.png?type=nfs260_260)
![[주주잡설] 놓치지 않을 거예요 (feat 자율주행 & 우주)](https://scs-phinf.pstatic.net/MjAyNTAyMTNfMTU5/MDAxNzM5NDQxNDUyMjI1.Tazdpmiaxt9q4N4mfI4oyzYSvnNWXpP0ubBK-3noXXYg.iLUrADd7mIHlDr-yqm3ckhDs1OCQfGTXCR9yprsMrR8g.JPEG/IMG_6384.jpeg?type=nfs260_260)
![[산업클럽] 범용 반도체 반등 시그널?](https://scs-phinf.pstatic.net/MjAyNTAyMTJfMzAw/MDAxNzM5Mjg2MjQ4MTU3.OtqH0BOTIO1Kwox9gre9GUfH8OB8debGEEB3Gu_2ORkg.MszIJv9n1-ECD3xCbkT1dNZW9si65yflQpzLvOKBFtcg.PNG/%EC%8A%A4%ED%81%AC%EB%A6%B0%EC%83%B7_2025-02-11_233905.png?type=nfs260_260)
![[산업클럽] 애플 폴더블 향 벨류체인 근황](https://scs-phinf.pstatic.net/MjAyNTAyMTBfMTkx/MDAxNzM5MTUzMDE5NDA3.Kexfn4NLIN3-AthD0OebBhO5nurQUol6-2MxbfGH5jwg.hSjKE6Gz8f3_0N2zdag-3yFbv6FtD1zEB4v4BaZP6zwg.JPEG/f182351371f70c548e08366a97f8bc32.jpg?type=nfs260_260)

![[주담통화] 대덕전자(353200) : AI 가속기 향 MLB 양산 시작](https://scs-phinf.pstatic.net/MjAyNTAyMTBfMjY2/MDAxNzM5MTc1MjMwNjE4.9M_SBD6kvjPWnmDmeevQc6VN743TliMdaOzNBvGCc3Yg.SRQ5JBX7oZIimxFQY_DgH22SMVNdipUj5D9hw0xpaNsg.PNG/image.png?type=nfs260_260)






